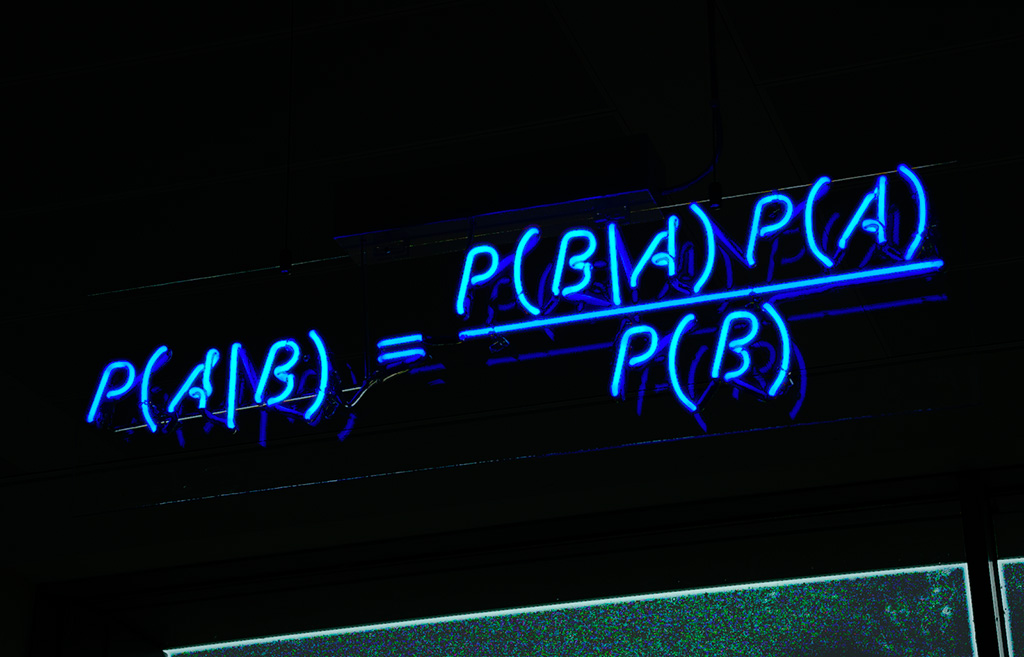1. Les origines de la méthode : recherche nucléaire et ordinateur électronique.
La méthode de Monte Carlo, pierre angulaire de la science computationnelle moderne, est née au milieu des années 1940, catalysée par la convergence de deux événements monumentaux : le développement du premier ordinateur électronique (ENIAC) et l’émergence de la recherche nucléaire à Los Alamos. Le nom de la méthode, proposé par Nicholas Metropolis, fait allusion au célèbre casino de Monte Carlo, soulignant ainsi les fondements de la méthode dans l'aléatoire et la probabilité.
L’origine de la méthode de Monte Carlo est intimement liée aux physiciens John von Neumann et Stanislaw Ulam. En travaillant sur des problèmes de diffusion de neutrons essentiels à la conception des armes nucléaires, S. Ulam a perçu le potentiel de l'échantillonnage statistique pour approcher des processus physiques complexes. Cette idée a été formalisée dans une lettre décrivant une approche stochastique pour modéliser le comportement des particules, l'ENIAC fournissant la puissance de calcul nécessaire pour sa mise en oeuvre.
La méthode consiste à utiliser des échantillons aléatoires pour résoudre des problèmes de calcul autrement intraitables. Par exemple, pour modéliser le transport des neutrons, l’historique individuel des particules est simulé, chaque interaction — qu'il s'agisse de diffusion, d'absorption ou de fission — étant régie par des règles probabilistes. En agrégant les résultats d’un grand nombre de ces trajectoires, les chercheurs pouvaient approcher le comportement de systèmes entiers, tâche jusque-là irréalisable en raison des limitations computationnelles. Cette capacité à modéliser statistiquement des processus physiques autrement insolubles a révolutionné la science computationnelle, permettant aux chercheurs d'explorer des systèmes aux interactions complexes et non linéaires.
L'idée de l'echantillonnage aléatoire n'était pas nouvelle, elle avait déjà été développée par Enrico Fermi dans les années 1930 dans le contexte de la modération des neutrons : des simulations stochastiques étaient réalisées manuellement à l’aide de simples calculateurs mécaniques. E. Fermi, pionnier de la physique nucléaire, aurait utilisé des techniques rudimentaires d'échantillonnage aléatoire pour estimer les résultats expérimentaux lors de calculs nocturnes. Cependant, le véritable potentiel de la méthode ne s’est révélé qu’avec la puissance de calcul de l'ENIAC, qui a permis des simulations à grande échelle validant l’efficacité et l'utilité pratique de l’approche.
La méthode de Monte Carlo s’est rapidement imposée, avec des applications se multipliant dans de nombreux domaines. Les premiers succès comprenaient des modèles de réactions thermonucléaires et des simulations d'ondes de choc, conduisant à une adoption plus large dans la physique statistique, la science des matériaux, voire dans des disciplines comme l’économie et la théorie des jeux. E. Fermi lui-même a continué à explorer le potentiel de la méthode, concevant même un dispositif analogique appelé FERMIAC pour simuler le transport des neutrons en deux dimensions. Cet outil précurseur a ouvert la voie à des implémentations numériques plus sophistiquées.
À la fin des années 1940, la méthode de Monte Carlo était devenue un outil fondamental à Los Alamos, avec des chercheurs développant des simulations de plus en plus complexes. En 1949, un symposium sur la méthode a réuni des scientifiques de divers horizons, accélérant son adoption à l’échelle mondiale. La flexibilité de la méthode la rendait adaptée à une vaste gamme d'applications, de l’étude des réactions nucléaires à l’exploration des transitions de phase.
Plus généralement, l’émergence de la méthode de Monte Carlo a transformé le calcul scientifique, en fournissant un cadre puissant pour traiter des problèmes complexes caractérisés par la présence d’incertitudes. Son évolution historique illustre l’interaction entre l’innovation mathématique et l’avancée technologique. Aujourd’hui, la méthode reste essentielle dans de nombreux domaines scientifiques, occupant une place particulière dans le Traitement du Signal notamment.
Dans un article du journal Los Alamos Science, Nicholas Metropolis décrit "The Beginning of the Monte Carlo method" [73]; voir aussi [40].
2. Echantillonnage d'une loi de probabilité
Considérons le problème d'obtenir des réalisations d'une variable aléatoire de distribution \(\pi\) donnée; pour simplifier l'exposé, nous supposerons que \(\pi\) est une loi de probabilité sur un espace mesurable \(\mathsf{X}\), \(\mathsf{X} \subseteq \mathbb{R}^d \).
L’échantillonnage exact. Il existe un grand nombre d’algorithmes d’échantillonnage aléatoire qui permettent de générer des vecteurs distribués suivant \(\pi\). L’échantillonnage exact est la méthode la plus simple, utilisée lorsque la distribution cible a une forme connue permettant un échantillonnage efficace. Par exemple, les distributions uniforme, gaussienne, gamma ou exponentielle disposent d’algorithmes bien établis, intégrés dans des librairies de calcul scientifique. La simulation de lois uniformes sur \([0,1]\) est obtenue par des procédures déterministes, comme les générateurs congruentiels; la méthode de Mersenne twister [70] est celle implémentée dans R, MATLAB et Python. Les algorithmes de simulation exacte reposent sur des techniques telles que la méthode d'inversion de la fonction de répartition, la méthode de rejet ou encore la méthode de Box-Muller pour les lois gaussiennes (cf. e.g. [32] pour de nombreux algorithmes de simulation exacte).
Monte Carlo par Chaîne de Markov. Les méthodes de Monte Carlo par Chaîne de Markov (MCMC) offrent une alternative puissante lorsque l’échantillonnage exact est difficile. Elles construisent une chaîne de Markov dont la distribution stationnaire existe, est unique et est la distribution cible \(\pi\). En simulant la chaîne pendant un nombre suffisant d’itérations, les points produits sont considérés comme une approximation de la loi \(\pi\). Ces méthodes sont particulièrement adaptées aux distributions cibles dont l'expression mathématique est complexe et connue seulement à une constante de normalisation près (voir e.g. [99, 86]).
Les algorithmes MCMC les plus connus sont Metropolis-Hastings et l’échantillonneur de Gibbs.
La méthode de Metropolis-Hastings par marche aléatoire symétrique constitue une variante simple de l’algorithme de Metropolis-Hastings [74, 6, 57, 81, 99]. Elle repose sur la génération de propositions en ajoutant à l’état courant \(X_i\) de la chaîne une perturbation aléatoire \(Y_i\) issue d’une distribution symétrique (par exemble gaussienne centrée). Chaque proposition \(X_i+Y_i\) est ensuite acceptée \((X_{i+1} = X_i +Y_i)\) ou rejetée \((X_{i+1} =X_i)\) selon une règle probabiliste visant à préserver la distribution cible \(pi\) comme distribution stationnaire de la chaîne. Cette méthode est facile à implémenter mais souffre de problèmes de convergence lente, surtout en grande dimension, où la performance décroît proportionnellement à la dimension \(d\) de l’espace.
L’algorithme MALA (Metropolis Adjusted Langevin Algorithm, [9, 91, 89]) améliore la méthode par marche aléatoire en intégrant le gradient du logarithme de la densité cible afin de guider les propositions. Cette approche permet une exploration plus efficace de l’espace, en particulier en grande dimension. MALA repose sur la dynamique de Langevin, un processus de diffusion dont la loi stationnaire coïncide avec la distribution cible. La simulation directe de cette diffusion étant généralement inapplicable en pratique, une discrétisation de type Euler est utilisée pour générer des propositions d’échantillons. Cette discrétisation exploite explicitement l’information de gradient, ce qui la rend nettement plus performante qu’une marche aléatoire classique. Une étape d’acceptation-rejet est ensuite intégrée pour corriger l’erreur induite par la discrétisation, assurant ainsi la convergence vers la distribution cible.
L’algorithme HMC (Hamiltonian Monte Carlo) est une autre extension récente de la méthode de Metropolis-Hastings, fondée sur la simulation de trajectoires issues de la dynamique hamiltonienne [37, 77]. À l’instar de l’algorithme MALA, HMC exploite le gradient du logarithme de la densité cible afin d’orienter efficacement l’exploration de l’espace d’état, notamment en grande dimension.
Dans certaines applications, des variantes non corrigées (par une étape d'acceptation-rejet) de MALA et HMC sont également utilisées [76, 91, 14]: bien qu’elles introduisent un léger biais puisque la loi limite n'est plus la loi cible, elles présentent souvent une meilleure vitesse de convergence et une complexité réduite, ce qui peut être avantageux dans des espaces de simulation de grande dimension [38]. Les méthodes d’Langevin non corrigées ont trouvé de nombreuses applications dans l’inférence bayésienne pour la restoration d'images (on peut citer, par exemple, [39, 68, 79, 104, 23]).
L’échantillonneur de Gibbs [53, 50, 20] constitue une méthode efficace lorsque les distributions conditionnelles associées à la loi cible \(\pi\) sont explicitement connues et faciles à échantillonner. Cette approche, qui met à jour successivement chacune des \(d\) composantes d'un point conditionnellement aux autres, est bien adaptée aux modèles hiérarchiques ou aux cadres bayésiens conjugués. Une variante améliorée, dite méthode de Gibbs partiellement marginalisée [102], consiste à intégrer analytiquement certaines variables avant leur mise à jour. Cette marginalisation partielle permet de réduire les corrélations entre échantillons successifs et d’accélérer la convergence de la chaîne. Toutefois, cette méthode repose sur la possibilité d’effectuer ces intégrations de manière explicite, ce qui limite son application à des modèles pour lesquels une telle simplification est tractable analytiquement.
Lorsque la simulation exacte sous une loi conditionnelle n'est pas possible, elle peut être remplacée par un tirage sous un échantillonneur MCMC construit pour admettre cette loi conditionnelle comme unique loi stationnaire : on parle alors de l'algorithme Metropolis-within-Gibbs. Ces algorithmes de type Gibbs, qui mettent à un jour une composante à la fois ou un bloc de composantes à la fois, font partie des méthodes dites "component-wise MCMC" ou "one-at-a-time MCMC" [99, Section 2.4], [63, 65, 100, 43].
Simulation par transformation ou push-forward. La simulation de variables aléatoires par transformation (également appelée méthode de «push-forward») consiste à appliquer une fonction déterministe et différentiable à une variable latente issue d’une distribution de base simple, typiquement une loi gaussienne ou uniforme [94]. Cette fonction, souvent paramétrée par un réseau de neurones, permet de transformer l’échantillon latent en un échantillon issu d’une distribution cible complexe. Cette approche est au cœur de nombreux modèles génératifs modernes, tels que les réseaux antagonistes génératifs (GAN), les autoencodeurs variationnels, et les flots normalisants. Ces approches offrent une grande flexibilité pour modéliser des distributions sur \(\mathbb{R}^d\) quand \(d\) est très grand, souvent uniquement connues à travers des données d’apprentissage. Elles permettent un échantillonnage efficace et se révèlent particulièrement bien adaptées à la génération de données synthétiques [12] ainsi qu’à l’inférence bayésienne [60].
Monte Carlo séquentiel. Les méthodes d’échantillonnage de Monte Carlo séquentiel (SMC), également appelées filtres particulaires, sont des techniques probabilistes utilisées pour estimer l’évolution d’un système dynamique caché à partir d’observations bruitées [22]. Elles reposent sur la propagation d’un ensemble d'échantillons ou ``particules'', chacunes associées à un poids d'importance, à travers des étapes successives de prédiction, de mise à jour (pondération selon la vraisemblance des observations), et de rééchantillonnage pour éviter la dégénérescence des poids. Ces techniques se révèlent particulièrement efficaces dans des contextes où les dynamiques sont non linéaires et/ou les bruits non gaussiens, rendant inopérantes les méthodes d'inférence séquentielle analytiques telles que le filtre de Kalman.
Au-delà des problèmes dynamiques, les méthodes SMC peuvent également être adaptées à des problèmes statiques, dans lesquels on cherche à générer des échantillons d'une distribution cible \(\pi\), constituant ainsi une alternative aux méthodes MCMC [22, Ch. SMC Samplers]. Dans ce cas, on construit une séquence artificielle de distributions intermédiaires reliant une distribution de référence \(\pi_0\), simple à échantillonner (par exemple, une loi gaussienne), à la distribution cible d’intérêt \(\pi\). Les échantillons évoluent alors au travers de cette séquence par des corrections graduelles, permettant une exploration progressive de l’espace. Cette approche est particulièrement pertinente pour les distributions multimodales, que les méthodes d’échantillonnage MCMC peuvent échouer à explorer de maniere exhaustive. Une stratégie couramment utilisée pour définir cette séquence consiste à appliquer à la distribution cible une série de puissances à exposants fractionnaires croissantes.
Modèles de diffusion de débruitage. Les modèles probabilistes de diffusion pour le débruitage [58, 97, 96] représentent une classe de modèles génératifs conçus pour synthétiser des distributions de données complexes en apprenant à inverser un processus stochastique de corruption prédéfini. Ces modèles simulent un processus de diffusion direct, généralement modélisé par une chaîne de Markov, qui altère progressivement les données par l’ajout de bruit gaussien au cours d’une séquence finie d’étapes intermédiaires visant une loi gaussienne. Paramétré par un réseau de neurones, le modèle est ensuite entraîné pour approcher le processus inverse de diffusion, ce qui permet la reconstruction itérative des données originales à partir d’entrées bruitées. Ce cadre favorise la génération d’échantillons de haute fidélité et a démontré des performances remarquables dans divers domaines, notamment la génération d’images, d’audio, de vidéos et de structures moléculaires. Des avancées récentes ont permis d’intégrer ces modèles dans des schémas bayésiens d’inversion [61, 28] et de développer des techniques de distillation, réduisant significativement le nombre d’évaluations nécessaires du réseau neuronal pour la génération d’échantillons [107, 69].
3. Intégration par Monte Carlo
Les méthodes de Monte Carlo sont aussi utilisées pour estimer la valeur numérique d'une intégrale
$$\begin{equation} \label{eq:definition:I} \mathcal{I} := \int_\mathsf{X} \phi(x) \, \mu(\mathrm{d} x), \end{equation}$$
où \(\phi\) est une fonction à valeur réelle et \(\mu\) désigne une mesure positive \(\sigma\)-finie. \(\mu\) peut être par exemple la mesure de Lebesgue sur \(\mathbb{R}^d\), ou la mesure de comptage sur un espace discret \(\mathsf{X}\) auquel cas \(\mathcal{I} = \sum_{x \in \mathsf{X}} \phi(x)\). Nous supposerons ici pour simplifier l'exposé, que \(\mathsf{X}\) est \(\mathbb{R}^d\) ou est un sous-ensemble mesurable de \(\mathbb{R}^d\).
Approximation Monte Carlo. L'estimation d'une intégrale par la méthode de Monte Carlo nécessite tout d'abord de relire le problème comme le calcul d'une espérance : trouver une loi de probabilité \(\pi\) sur \(\mathsf{X}\) muni d'une tribu \(\mathcal{X}\), et une fonction mesurable \(f: \mathsf{X} \to \mathbb{R}\), \(\pi\)-intégrable, telles que
$$\begin{equation}\label{eq:Ienesperenance} \mathcal{I} =\int_\mathsf{X} f(x) \pi(\mathrm{d} x) = \mathbb{E}_\pi\left[f(X) \right]. \end{equation}$$
La seconde étape consiste à utiliser une procédure d'échantillonnage Monte Carlo produisant des points \(\{X_1, \cdots, X_n \}\) approchant la loi \(\pi\), et à définir l'estimateur \(\widehat{\mathcal{I}}_n\) de \(\mathcal{I}\) :
$$\begin{equation}\label{eq:def:Ichapeau} \widehat{\mathcal{I}}_n := \frac{1}{n} \sum_{i=1}^n f(X_i). \end{equation}$$
Contrairement à d'autres méthodes numériques d'intégration (voir e.g. [29]), l'estimateur requiert l'évaluation de la fonction \(f\) mais ne nécessite pas le calcul de dérivées de \(f\). Il s'agit de plus d'une méthode numérique aléatoire : étant donnée une réprésentation \((f,\pi)\) de \(\mathcal{I}\) (voir Eq. \eqref{eq:Ienesperenance}), deux appels successifs à la méthode produiront deux suites différentes de points \(\{X_1, \cdots, X_n\}\) et donc deux valeurs distinctes de l'estimateur \(\widehat{\mathcal{I}}_n\).
Le bien-fondé des méthodes d'intégration par Monte Carlo repose sur des théorèmes de la théorie des probabilités.
Consistance. Tout d'abord, la loi des grands nombres établit la consistance forte de l'estimateur \(\widehat{\mathcal{I}}_n\) en donnant des conditions suffisantes sur le mécanisme d'échantillonnage des points \(X_1, X_2, \cdots\) garantissant
$$\begin{equation} \label{eq:LGN} \lim_{n \to \infty} \widehat{\mathcal{I}}_n = \mathcal{I} \qquad \text{avec probabilité $1$.} \end{equation}$$
On trouve dans la littérature des conditions suffisantes pour la loi des grands nombres, applicables à différents schémas de simulation : par exemple, le cas où les points \(\{X_i, i \geq 1 \}\) sont indépendants et identiquement distribués (i.i.d.) de loi \(\pi\) [11, Section 6], ou sont une chaîne de Markov ergodique d'unique loi invariante \(\pi\) [75, Chapitre 17], ou sont la réalisation d'un mécanisme d'échantillonnage adaptatif i.e. qui évolue au cours des itérations en apprenant du comportement passé de l'algorithme (e.g. [47]).
Contrôle d'erreur d'approximation. Le contrôle de l'erreur d'approximation \(\widehat{\mathcal{I}}_n-\mathcal{I}\) repose essentiellement sur un Théorème de la Limite Centrale et, dans une moindre mesure, sur des contrôles d'erreur dans \(L^p\) dont l'erreur quadratique \(\mathbb{E}\left[ | \widehat{\mathcal{I}}_n-\mathcal{I}|^2 \right]\) (voir e.g. [110] pour des points \(\{X_1, X_2, \cdots \}\) produits par un MCMC). Sous des conditions sur le mécanisme d'échantillonnage (voir par exemple [11, Section 27], [75, Chapitre 17] et [48] pour respectivement, le cas de points i.i.d. de loi \(\pi\), le cas d'une chaîne de Markov ergodique ayant \(\pi\) pour unique loi invariante, le cas d'une méthode de Monte Carlo adaptative), il existe une variance \(\upsilon\) strictement positive telle que
$$\begin{equation}\label{eq:TCL} \lim_{n \to \infty} \sqrt{n} \left( \widehat{\mathcal{I}}_n-\mathcal{I}\right) = \mathcal{N}(0, \upsilon) \qquad \text{en loi.} \end{equation}$$
Autrement dit, lorsque le nombre \(n\) de points dans la somme de Monte Carlo est assez grand, l'approximation \(\widehat{\mathcal{I}}_n\) fluctue autour de la quantité cible \(\mathcal{I}\) et ces fluctuations sont distribuées selon une loi gaussienne centrée de variance \(\upsilon/ n\). Cette vitesse en \(n^{-1}\) est la force des méthodes d'intégration Monte Carlo : elle ne requiert aucune hypothèse sur le niveau de régularité de l'intégrande, et ne dépend pas de la dimension \(d\) de l'espace de simulation (cf. [29, Chapitres 4 et 5] pour des méthodes d'intégration numérique déterministes dont l'erreur d'approximation décroît en \(n^{\frac{-1}{d}}\). En revanche, \(d\) apparaît dans l'expression de la variance asymptotique \(\upsilon\).
L'existence d'un Théorème de la Limite Centrale est le point de départ du calcul d'intervalles de confiance asymptotiques pour la quantité inconnue \(\mathcal{I}\), à condition de connaître la variance \(\upsilon\) ou de disposer d'un estimateur consistant de \(\upsilon\). Lorsque les points \(\{X_i, i \geq 1 \}\) sont i.i.d. de loi \(\pi\), \(\upsilon\) est le moment centré d'ordre deux de \(f(X)\), \(X \sim \pi\); cela n'est plus vrai lorsque les points \(\{X_i, i \geq 1 \}\) sont une chaîne de Markov. La théorie des chaînes de Markov établit différentes expressions de \(\upsilon\) : cf. [75, Eq. (17.13)] pour les chaînes à valeur dans un espace \(\mathsf{X}\) au plus dénombrable; [75, Théorème 17.5.3] pour les chaînes à valeur dans \(\mathbb{R}^d\). Néanmoins, aucune n'a de forme close en dehors des situations jouet. Par suite, des estimateurs ont été proposés, basés sur des temps de renouvellement, sur une approche par moyennes locales ou sur une approche spectrale (voir e.g. [59, 64, 45).
Méthodes adaptatives. Pour un problème d'intégration numérique \(\eqref{eq:definition:I}\) donné, il n'y a pas unicité de la représentation \((f,\pi)\) vérifiant \(\eqref{eq:Ienesperenance}\): par exemple, si \(\pi\) est absolument continue par rapport à la probabilité \(\nu\) on a \[ \int_\mathsf{X} f(x) \, \pi(\mathrm{d} x) = \int_\mathsf{X} f(x) \, \frac{\mathrm{d} \pi}{\mathrm{d} \nu}(x) \, \nu(\mathrm{d} x), \] où \(\frac{\mathrm{d} \pi}{\mathrm{d} \nu}\) désigne la dérivée de Radon-Nikodym de \(\pi\) par rapport à \(\nu\); on en déduit que \((f \, \frac{\mathrm{d} \pi}{\mathrm{d} \nu}, \nu)\) est une autre représentation. Une fois la probabilité \(\pi\) choisie, il n'y a pas unicité de l'algorithme permettant de produire des points \(\{X_1, X_2, \cdots \}\) approchant \(\pi\).
Il est alors naturel de rechercher une écriture sous la forme \eqref{eq:Ienesperenance} puis une méthode d'échantillonnage, optimales. La réponse dépend du critère d'optimalité retenu : un des critères les plus populaires est la minimisation de la variance asymptotique dans \eqref{eq:TCL} (voir e.g. [4, Chapitre 6] pour les méthodes d'échantillonnage d'importance); pour certains échantillonneurs MCMC, c'est le comportement limite de cette variance quand \(d \to \infty\) qui a été considéré, le critère devenant alors indépendant de la fonctionnelle \(f\) dans \eqref{eq:def:Ichapeau} (cf. les papiers fondateurs de la méthode de scaling, [51, 88]). Ces critères s'écrivant souvent comme des espérances non explicites, des méthodes d'échantillonnage adaptatives sont apparues. L'idée est de chercher la meilleure décomposition et/ou la meilleure méthode de simulation dans une famille paramétrique: pour ce faire, une procédure de simulation des points \(\{X_1, X_2, \cdots \}\) et une procédure d'apprentissage du paramètre optimal sont menées en parallèle, et interagissent régulièrement : le paramètre est mis à jour en utilisant les points produits par l'algorithme, et l'échantillonneur utilise le mécanisme indexé par le paramètre courant. Ces techniques adaptatives ont fait l'objet de nombreux travaux au début des années 2000; citons par exemple [18, 26, 67] pour des méthodes d'échantillonnage d'importance adaptatif, et pour les méthodes MCMC adaptatives, le travail pionnier [55] et les articles de synthèse [3, 5, 80].
Ces méthodes adaptatives doivent toutefois être utilisées avec précaution car l'adaptation peut détruire la convergence, comme illustré par l'exemple suivant donné dans [2].
Considérons le cas de la simulation d'une chaîne de Markov à valeur dans \(\{0,1 \}\), et de loi invariante \(\pi := (\frac{1}{2}, \frac{1}{2})\). Une telle chaîne peut être obtenue en utilisant la matrice de transition \(P\) mais aussi la matrice \(Q\)
\[ P := \begin{bmatrix} 1-p & p \\ p & 1-p \end{bmatrix} \qquad Q := \begin{bmatrix} 1-q & q \\ q & 1-q \end{bmatrix} \]
où \(p \neq q\), et \(p,q \in ]0,1[\). Construisons une troisième chaîne selon l'algorithme adaptatif suivant : si \(X_n =0\), alors \(X_{n+1}\) est obtenu en utilisant la transition \(P\), et si \(X_{n} =1\), la transition \(Q\) est utilisée. Cette chaîne est encore markovienne, et a pour mesure invariante \(\pi^{\mathrm{ad}} := (\frac{q}{p+q}, \frac{p}{p+q})\). On a \(\pi \neq \pi^{\mathrm{ad}}\), ce qui illustre le fait que choisir aléatoirement un mécanisme de transition, définit des points \(\{X_1, X_2, \cdots \}\) qui approchent \(\pi^{\mathrm{ad}}\) même si chaque mécanisme a la mesure invariante \(\pi\).
Des conditions ont alors été énoncées dans la littérature pour étudier ces procédures adaptatives. En MCMC par exemple, il suffit essentiellement de vérifier la condition de containment qui requiert que la famille paramétrique d'algorithmes considérée ait des propriétés d'ergodicité semblables; et la propriété de diminishing adaptation qui requiert que l'adaptation s'estompe dans le temps [90, 47].
Diagnostic de convergence. Si les résultats théoriques garantissent que \(\widehat{\mathcal{I}}_n\) converge vers \(\mathcal{I}\) lorsque le nombre de points \(n\) dans la somme de Monte Carlo tend vers l'infini (voir \eqref{eq:LGN}), la question demeure du choix de \(n\) en pratique. Tout d'abord, \(n\) doit être assez grand pour garantir un niveau de précision dans l'approximation de \(\mathcal{I}\) par \(\widehat{\mathcal{I}}_n\). De plus, lorsque les méthodes de simulation ne sont pas exactes i.e. lorsque les tirages \(\{X_1, X_2, \cdots \}\) ne sont pas de loi \(\pi\), s'ajoute la nécessité d'itérer le mécanisme d'échantillonnage assez longtemps pour considérer que la loi d'un tirage \(X_i\) est proche de \(\pi\).
Les résultats théoriques développés pour le contrôle d'erreur Monte Carlo et le contrôle de convergence des échantillonneurs sont, la plupart du temps, inexploitables en pratique pour déterminer un nombre de points minimal dans la somme \eqref{eq:def:Ichapeau} garantissant une précision donnée. Ces contrôles dépendent en effet de quantités inconnues, outre qu'ils reflètent des contrôles "pire cas" peu adaptés à un problème spécifique \(\mathcal{I}\) [75, Chapitre 15],[36, 35]. Par suite, différents diagnostics de convergence ont été proposés dans la littérature; voir par exemple les articles de synthèse [17, 72, 27, 93].
Garantir un niveau maximal de fluctuation Monte Carlo avec grande probabilité, pour un choix de \(n \) assez grand, peut être obtenu à l'aide de l'estimation d'un intervalle de confiance asymptotique (voir e.g. [44, Section 3]).
Dans le cas d'un mécanisme d'échantillonnage markovien, les tests de proximité de la loi des points \(X_i\) à \(\pi\) les plus populaires sont : la taille effective d'échantillon, qui évalue la taille d'un échantillon i.i.d. nécessaire pour atteindre la même variance asymptotique que le nuage de points \(\{X_1, \cdots, X_n\}\) [87, Section 12.3.5]; la vitesse de décroissance vers zero de la fonction d'auto-corrélation, qui caractérise la vitesse d'oubli du passé de la chaîne de Markov; le diagnostic de Gelman-Rubin, qui évalue si la chaîne a oublié sa condition initiale [52, 15]. Il ne faut néanmoins pas perdre de vue que "Diagnostics can only reliably be used to determine a lack of convergence and not detect convergence per se" [16].
4. Quelques exemples d'hybridation
De nombreux algorithmes exploitent les procédures de Monte Carlo, par exemple pour définir une technique de déplacement dans un espace de configurations possibles \(\mathsf{X}\) en mimant une méthode de simulation Monte Carlo, ou comme un outil d'approximation numérique d'une intégrale non explicite. Nous présentons ici quelques exemples issus d'hybridations entre procédures Monte Carlo et algorithmes d'optimisation, particulièrement pertinents pour le traitement du signal.
Recuit simulé. L'algorithme de Hastings peut être lu comme une méthode construisant des configurations \(x \) dans un espace \(\mathsf{X} \) de manière itérative, toute nouvelle configuration \(x' \) ayant une probablité \(\pi(x') \) plus élevée que la probabilité \(\pi(x) \) du point courant \(x \) étant acceptée. De façon équivalente, en écrivant \(\pi(x) = (\frac{1}{Z_T}) \, \exp(- F(x)/T)\), toute nouvelle configuration \(x' \) d'énergie \(F(x') \) plus basse que l'énergie \(F(x) \) du point courant \(x\), est acceptée. En cela, l'algorithme favorise les déplacements vers les minima de \(F\). Si le choix de la température \(T \) ne joue pas de rôle sur la monotonie de \(\pi\), il joue un rôle crucial dans la capacité de l'échantillonneur à se déplacer entre les modes de \(\pi \) et donc dans la capacité de l'algorithme d'optimisation à s'extraire des minima locaux. L'algorithme de recuit simulé [66, 109]s'appuie sur ce constat pour proposer une méthode de minimisation d'une fonction objectif \(F\); la méthode alterne étape de simulation et étape de mise à jour de la température \(T\), la difficulté étant de choisir la vitesse à laquelle la température est refroidie (voir e.g. [41, 8, 54, 1]).
Algorithmes évolutionnaires. Les algorithmes évolutionnaires sont des méthodes d'optimisation inspirées de l'évolution darwinienne de la population : \(N \) points parents peuvent être sélectionnés, recombinés, mutés et reproduits pour être remplacés par une population plus adaptée. Dans les algorithmes dits stratégies d'évolution (ES) [95, 83, 10], la procédure d'optimisation maintient un nuage de \(N \) points qu'elle fait évoluer pour qu'il se concentre autour des minima de la fonction objectif \(F\). L'étape de mutation se fait par simulation Monte Carlo; la sélection des points survivants repose sur la valeur de la fonction objectif en ces points. Par exemple, pour les ES {\it par adaptation de la matrice de covariance}, la solution \(x^\star \) est approchée par un nuage de points échantillonnés sous une loi gaussienne multivariée; l'algorithme adapte l'espérance et la variance de la loi de façon à favoriser la simulation de la nouvelle génération de points dans des directions définies par les valeurs de \(F \) en les points parents. La difficulté est la mise à jour de la matrice de covariance (voir par exemple [56, 62, 34, 101]).
Approximation Stochastique. L'Approximation Stochastique (AS), méthode introduite en 1951 par Robbins et Monro [85], est une procédure itérative pour la recherche de zeros d'un champs \(h: \mathbb{R}^d \to \mathbb{R}^d \) dans les situations où l'on ne dispose que d'oracles stochastiques \(H(\omega, X) \) du champs \(h(\omega) \) et ce, pour tout \(\omega\). Etant données une suite de pas d'apprentissage \(\{\gamma_t, t \geq 1\} \) et une valeur initiale \(\omega_0\), l'AS produit séquentiellement des itérés selon la formule \(\omega_{t+1} = \omega_t + \gamma_{t+1} H(\omega_t, X_{t+1}) \) où \(X_{t+1} \) collecte l'aléa nécessaire à la définition de l'oracle de \(h(\omega_t)\). Dans de nombreuses situations, \(h \) est une espérance non explicite et l'oracle \(H(\omega_t, X_{t+1}) \) est construit par intégration Monte Carlo. L'exemple le plus célèbre est certainement l'algorithme de Gradient Stochastique pour lequel \(h \) est un champs de gradient. En apprentissage par {\it batch} par exemple, \(h \) est le gradient d'une fonction de perte empirique \(h(\omega) = N^{-1} \sum_{i=1}^N \nabla \ell_i(\omega) \) qui s'écrit aussi \(\mathbb{E}\left[\nabla \ell_I(\omega) \right] \) où \(I \) est la loi uniforme sur \(\{1, \cdots, N \}\); lorsque \(N \) est grand de sorte que le coût de calcul du gradient exact est prohibitif, l'algorithme de Gradient Stochastique remplace \(h(\omega) \) par une approximation Monte Carlo obtenue en choisissant aléatoirement un ensemble \(X \) de \(\mathsf{b} \) exemples parmi les \(N \) : \(H(\omega,X) = \mathsf{b}^{-1} \sum_{i \in X} \nabla \ell_i(\omega) \) (voir e.g. [13] pour des extensions du gradient stochastique en Apprentissage). L'AS s'applique à d'autres champs de vecteurs que des champs de gradient; en posant \(h(\omega) := \mathsf{T}(\omega) - \omega\), c'est en particulier un algorithme itératif aléatoire pour la recherche de points fixes d'un opérateur \(\mathsf{T} \) lorsque \(\mathsf{T} \) est non explicite mais admet une approximation Monte Carlo (voir l'article de synthèse [33], ou l'exemple particulier de versions stochastiques de l'algorithme Expectation-Maximization [31, 19]). Si l'ajout d'un aléa par approximation Monte Carlo permet de lever un verrou numérique, il n'en reste pas moins qu'il introduit une erreur stochastique et donc de la variance dans le processus itératif. Des techniques Monte Carlo de réduction de variance sont souvent couplées à des schemas d'AS ; tout d'abord introduites pour le Gradient Stochastique sous le nom de SAGA [30], SVRG [84]}, SARAH [78] et SPIDER [42, 105], elles ont ensuite été étendues à des AS plus généraux (voir [33] et [21, 49, 82] pour ne citer que quelques exemples).
Les méthodes d’AS ont trouvé de nombreuses applications dans l’inférence bayésienne empirique, notamment dans les domaines du traitement du signal et de l’image. On peut citer, par exemple, [103, 71, 98], qui illustrent des avancées récentes dans l’estimation de hyper-paramètres de regularization, le défloutage myope, ainsi que l’inférence bayésienne avec des lois a priori représentées par des modèles génératifs multimodaux image-texte de type Stable Diffusion.
Algorithmes itératifs stochastiques. Selon les applications considérées, des algorithmes itératifs déterministes de la forme \(\bar \omega_{t+1} = \mathsf{T}_t(\bar \omega_t)\), peuvent nécessiter des approximations numériques. Dès lors que le verrou computationnel porte sur le calcul d'une somme ou d'une intégrale, les méthodes de Monte Carlo sont exploitées pour construire des approximations de nature stochastique, ce qui se traduit par l'algorithme \(\omega_{t+1} = \hat{ \mathsf{T}}_t(\omega_t) \) où \(\hat{ \mathsf{T}}_t \) est une application aléatoire. Dans l'analyse du bien-fondé de ces algorithmes perturbés, l'enjeu est de contrôler l'erreur stochastique introduite à chaque itération, conséquence de la substitution de l'opérateur \( \mathsf{T}_t \) par l'opérateur \(\hat{ \mathsf{T}}_t\), afin de montrer que les erreurs cumulées restent suffisamment maîtrisées pour que l'algorithme \(\{\omega_t, t \geq 0\} \) ne dévie pas trop du "squelette" déterministe \(\{\bar \omega_t, t \geq 0 \} \) et hérite de son comportement. En analyse de convergence asymptotique par exemple, il est ainsi souvent demandé que le biais et la variance de l'erreur stochastique décroissent avec l'indice d'itération. Citons quelques exemples de tels algorithmes et de références : l'algorithme Monte Carlo EM [106, 46], l'algorithme de gradient proximal stochastique [92], l'algorithme de descente miroir stochastique [108], des algorithmes forward-backward stochastiques [25], des opérateurs \( \mathsf{T}_t \) quasi non expansifs [24], un algorithme d'inférence variationnelle [7].
Références
[1]
C. Andrieu, L. A. Breyer et A. Doucet :
Convergence of simulated annealing using Foster-Lyapunov criteria.
Journal of Applied Probability , 38(4)
975–994, 2001.
[2]
C. Andrieu et E. Moulines :
On the ergodicity properties of some adaptive MCMC algorithms.
The Annals of Applied Probability ,
16(3) 1462 -- 1505, 2006.
[3]
C. Andrieu et J. Thoms :
A tutorial on adaptive MCMC.
Statistics and Computing , 18, issue 4, Publisher: Springer Netherlands
343 -- 373, décembre 2008.
[4]
S. Asmussen et P.W. Glynn :
Stochastic Simulation: Algorithms and Analysis .
Stochastic Modelling and Applied Probability. Springer New York,
2007.
[5]
Y. Atchadé, G. Fort, E. Moulines et P. Priouret :
Adaptive Markov chain Monte Carlo: theory and methods , page
32–51.
Cambridge University Press, 2011.
[6]
A.A. Barker :
Monte Carlo Calculations of the Radial Distribution Functions for a Proton-Electron Plasma.
Australian Journal of Physics , 18, 119--134, 1965.
[7]
F. Bertholom, R. Douc et F. Roueff :
Asymptotics of Alpha-Divergence Variational Inference Algorithms with Exponential Families.
In A. Globerson,
L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak et C. Zhang, éditeurs :
Advances in Neural Information Processing Systems, volume 37, pages
106237--106263. Curran Associates, Inc., 2024.
[8]
D. Bertsimas et J. Tsitsiklis :
Simulated Annealing.
Statistical Science , 8, 02 1993.
[9]
J. Besag :
In discussion of ‘Representations of knowledge in complex systems’ by U. Grenander and M.I. Miller.
Journal of the Royal Statistical Society, Serie B ,
56 591--592, 1994.
[10]
H.G. Beyer et H.P. Schwefel :
Evolution strategies – A comprehensive introduction.
Natural Computing , 1 3--52, 2002.
[11]
P. Billingsley :
Probability and measure .
A Wiley-Interscience publication. Wiley, New York, 3. ed édition,
1995.
[12]
C. M. Bishop et H. Bishop :
Deep learning .
Springer International Publishing, Cham, Switzerland, 2024 édition,
novembre 2023.
[13]
L. Bottou, F. E. Curtis et J. Nocedal :
Optimization Methods for Large-Scale Machine Learning.
SIAM Review , 60(2) 223--311, 2018.
[14]
N. Bou-Rabee et A. Eberle :
Mixing time guarantees for unadjusted Hamiltonian Monte Carlo.
Bernoulli , 29(1) 75 -- 104, 2023.
[15]
S. P. Brooks et A. Gelman :
General Methods for Monitoring Convergence of Iterative Simulations.
Journal of Computational and Graphical Statistics ,
7(4) 434--455, 1998.
[16]
S. P. Brooks, P. Giudici et A. Philippe :
Nonparametric Convergence Assessment for MCMC Model Selection.
Journal of Computational and Graphical Statistics ,
12(1) 1--22, 2003.
[17]
S. P. Brooks et G. O. Roberts :
Convergence assessment techniques for Markov chain Monte Carlo.
Stat. Comput. , 8(4) 319--335, 1998.
[18]
O. Cappé, R. Douc, A. Guillin, J.-M. Marin et C. P. Robert :
Adaptive Importance Sampling in General Mixture Classes.
Statistics and Computing , 18(4)
447–459, décembre 2008.
[19]
O. Cappé et E. Moulines :
On-Line Expectation-Maximization Algorithm for Latent Data Models.
Journal of the Royal Statistical Society. Series B (Statistical Methodology),
71(3) 593--613, 2009.
[20]
G. Casella et E.I. George :
Explaining the Gibbs Sampler.
The American Statistician , 46(3)
167--174, 1992.
[21]
J. Chen, J. Zhu, Y. W. Teh et T. Zhang :
Stochastic expectation maximization with variance reduction.
NeurIPS , 31, 2018.
[22]
N. Chopin et O. Papaspiliopoulos :
An introduction to sequential Monte Carlo .
Springer series in statistics. Springer Nature, Cham, Switzerland,
2020 édition, octobre 2020.
[23]
F. Coeurdoux, N. Dobigeon et P. Chainais :
Normalizing flow sampling with langevin dynamics in the latent space.
Mach. Learn. , 113(11-12) 8301--8326,
décembre 2024.
[24]
P.L. Combettes et J.C. Pesquet :
Stochastic Quasi-Fejér Block-Coordinate Fixed Point Iterations with Random Sweeping.
SIAM J. Optim. , 25 1221--1248, 2015.
[25]
P.L. Combettes et J.C. Pesquet :
Stochastic Approximations and Perturbations in Forward-Backward Splitting for Monotone Operators.
Pure Appl. Funct. Anal , 1 13--37,
2016.
[26]
J.-M. Cornuet, J.-M. Marin, A. Mira et C.P. Robert :
Adaptive Multiple Importance Sampling.
Scandinavian Journal of Statistics ,
39(4) 798--812, 2012.
[27]
M. K. Cowles et B. P. Carlin :
Markov Chain Monte Carlo Convergence Diagnostics: A Comparative Review.
Journal of the American Statistical Association ,
91(434) 883--904, 1996.
[28]
G. Daras, H. Chung, C.-H. Lai, Y. Mitsufuji, J.C. Ye, P. Milanfar, A.G. Dimakis et M. Delbracio :
A survey on diffusion models for inverse problems, 2024.
[29]
P.J. Davis et P. Rabinowitz :
Methods of Numerical Integration .
Computer Science and Applied Mathematics. Academic Press, 1984.
[30]
A. Defazio, F. Bach et S. Lacoste-Julien :
SAGA: A fast incremental gradient method with support for non-strongly convex composite objectives.
NeurIPS , 27, 2014.
[31]
B. Delyon, M. Lavielle et E. Moulines :
Convergence of a Stochastic Approximation Version of the EM Algorithm.
Ann. Statist. , 27(1), 1999.
[32]
L. Devroye :
Non-Uniform Random Variate Generation .
Springer-Verlag, 1986.
[33]
A. Dieuleveut, G. Fort, E. Moulines et H.-T. Wai :
Stochastic Approximation Beyond Gradient for Signal Processing an Machine Learning.
IEEE Transactions on Signal Processing ,
71 3117--3148, 2023.
[34]
Y. Diouane, S. Gratton et L.N. Vicente :
Globally convergent evolution strategies.
Math. Program. , 152 467--490, 2015.
[35]
R. Douc, G. Fort, E. Moulines et P. Soulier :
Practical Drift Conditions for Subgeometric Rates of Convergence.
The Annals of Applied Probability ,
14(3) 1353--1377, 2004.
[36]
R. Douc, E. Moulines et J.S. Rosenthal :
Quantitative Bounds on Convergence of Time-Inhomogeneous Markov Chains.
The Annals of Applied Probability ,
14(4) 1643--1665, 2004.
[37]
S. Duane, A.D. Kennedy, B.J. Pendleton et D. Roweth :
Hybrid Monte Carlo.
Physics Letters B , 195(2) 216--222,
1987.
[38]
A. Durmus et E. Moulines :
Nonasymptotic convergence analysis for the unadjusted Langevin algorithm.
Ann. Appl. Probab. , 27(3) 1551--1587,
2017.
[39]
A. Durmus, E. Moulines et M. Pereyra :
A proximal markov chain monte carlo method for bayesian inference in imaging inverse problems: When langevin meets moreau.
SIAM Review , 64(4) 991--1028, 2022.
[40]
R. Eckhardt :
Stan Ulam, John von Neumann, and the Monte Carlo Method.
Los Alamos Science , 15 131--136, 1987.
[41]
R.W. Eglese :
Simulated Annealing: A tool for Operational Research.
European Journal of Operational Research ,
46(3) 271--281, 1990.
[42]
C. Fang, C. J. Li, Z. Lin et T. Zhang :
SPIDER: Near-optimal non-convex optimization via stochastic path-spider-boost differential estimator.
NeurIPS , 31, 2018.
[43]
G.O. Filippo Ascolani, F.and Roberts et G. Zanella :
Scalability of Metropolis-within-Gibbs schemes for high-dimensional Bayesian models,
2024.
[44]
J. M. Flegal, M. Haran et G. L. Jones :
Markov Chain Monte Carlo: Can We Trust the Third Significant Figure?
Statistical Science , 23(2) 250 -- 260,
2008.
[45]
J.M. Flegal et G.L. Jones :
Batch means and spectral variance estimators in Markov chain Monte Carlo.
Ann. Statist. , 38(2) 1034 -- 1070,
2010.
[46]
G. Fort et E Moulines :
Convergence of the Monte Carlo Expectation Maximization for curved exponential families.
Ann. Statist. , 31(4) 1220--1259, 2003.
[47]
G. Fort, E. Moulines et P. Priouret :
Convergence of adaptive and interacting Markov chain Monte Carlo algorithms.
Ann. Statist. , 39(6) 3262 -- 3289,
2011.
[48]
G. Fort, E. Moulines, P. Priouret et P. Vandekerkhove :
A central limit theorem for adaptive and interacting Markov chains.
Bernoulli , 20(2) 457 -- 485, 2014.
[49]
G. Fort, E. Moulines et H.-T. Wai :
A Stochastic Path Integrated Differential Estimator Expectation Maximization Algorithm.
NeurIPS, NIPS'20, Red Hook, NY, USA, 2020. Curran
Associates Inc.
[50]
A.E. Gelfand et A.F.M. Smith :
Sampling-Based Approaches to Calculating Marginal Densities.
Journal of the American Statistical Association ,
85(410) 398--409, 1990.
[51]
A. Gelman, W. R. Gilks et G. O. Roberts :
Weak convergence and optimal scaling of random walk Metropolis algorithms.
The Annals of Applied Probability ,
7(1) 110 -- 120, 1997.
[52]
A. Gelman et D. B. Rubin :
Inference from Iterative Simulation Using Multiple Sequences.
Statist. Sci. , 7(4) 457--472, 1992.
[53]
S. Geman et D. Geman :
Stochastic Relaxation, Gibbs Distributions, and the Bayesian Restoration of Images.
IEEE Transactions on Pattern Analysis and Machine Intelligence ,
PAMI-6(6) 721--741, 1984.
[54]
H. Haario et E. Saksman :
Simulated Annealing Process in General State Space.
Advances in Applied Probability , 23(4)
866–893, 1991.
[55]
H. Haario, E. Saksman et J. Tamminen :
An adaptive Metropolis algorithm.
Bernoulli , 7(2) 223 -- 242, 2001.
[56]
N. Hansen et A. Ostermeier :
Adapting arbitrary normal mutation distributions in evolution strategies: the covariance matrix adaptation.
In Proceedings of IEEE International Conference on Evolutionary Computation, pages 312--317, 1996.
[57]
W.K. Hastings :
Monte Carlo Sampling Methods Using Markov Chains and Their Applications.
Biometrika , 57(1) 97--109, 1970.
[58]
J. Ho, A. Jain et P. Abbeel :
Denoising diffusion probabilistic models.
Advances in Neural Information processing systems ,
33 6840--6851, 2020.
[59]
J. P. Hobert, G. L. Jones, B. Presnell et J.S. Rosenthal :
On the Applicability of Regenerative Simulation in Markov Chain Monte Carlo.
Biometrika , 89(4) 731--743, 2002.
[60]
M. Holden, M. Pereyra et K. C. Zygalakis :
Bayesian imaging with data-driven priors encoded by neural networks.
SIAM Journal on Imaging Sciences ,
15(2) 892--924, 2022.
[61]
Y. Janati, E. Moulines, J. Olsson et A. Oliviero-Durmus :
Bridging diffusion posterior sampling and monte carlo methods: a survey.
Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, 383(2299)
20240331, 2025.
[62]
G.A. Jastrebski et D.V. Arnold :
Improving Evolution Strategies through Active Covariance Matrix Adaptation.
In 2006 IEEE International Conference on Evolutionary Computation, pages 2814--2821, 2006.
[63]
A.A. Johnson, G.J. Jones et R.C. Neath :
Component-Wise Markov Chain Monte Carlo: Uniform and Geometric Ergodicity under Mixing and Composition.
Statistical Science , 28(3) 360 -- 375,
2013.
[64]
G.L. Jones, M. Haran, B.S. Caffo et R. Neath :
Fixed-Width Output Analysis for Markov Chain Monte Carlo.
Journal of the American Statistical Association ,
101(476) 1537--1547, 2006.
[65]
G.L. Jones, G.O. Roberts et J.S. Rosenthal :
Convergence of conditional Metropolis-Hastings samplers.
Advances in Applied Probability , 46(2)
422 -- 445, 2014.
[66]
S. Kirkpatrick, C. D. Gelatt et M. P. Vecchi :
Optimization by Simulated Annealing.
Science , 220(4598) 671--680, 1983.
[67]
D. P. Kroese, R. Y. Rubinstein et P. W. Glynn :
Chapter 2 - The Cross-Entropy Method for Estimation.
In C.R. Rao et V. Govindaraju, éditeurs :
Handbook of Statistics, volume 31 de Handbook of Statistics,
pages 19--34. Elsevier, 2013.
[68]
R. Laumont, V. De Bortoli, A. Almansa, J. Delon, A. Durmus et M. Pereyra :
Bayesian imaging using Plug Play priors: when Langevin meets Tweedie.
SIAM Journal on Imaging Sciences ,
15(2) 701--737, 2022.
[69]
X. Liu, C. Gong et Q. Liu :
Flow straight and fast: Learning to generate and transfer data with rectified flow.
In The Eleventh International Conference on Learning Representations, 2023.
[70]
M. Matsumoto et T. Nishimura :
Mersenne twister: a 623-dimensionally equidistributed uniform pseudo-random number generator.
8(1) 3--30, 1998.
[71]
C. K. Mbakam, M. Pereyra et J.-F. Giovannelli :
Marginal Likelihood Estimation in Semiblind Image Deconvolution: A Stochastic Approximation Approach.
SIAM Journal on Imaging Sciences ,
17(2) 1206--1254, 2024.
[72]
K. L. Mengersen, C. P. Robert et C. Guihenneuc-Jouyaux :
MCMC Convergence Diagnostics: A Review.
In Bayesian Statistics 6: Proceedings of the Sixth Valencia International Meeting June 6-10, 1998. Oxford University Press, 08 1999.
[73]
N. Metropolis :
The Beginning of the Monte Carlo Method.
Los Alamos Science, Special Issue , 15
125--130, 1987.
[74]
N. Metropolis, A. W. Rosenbluth, M. N. Rosenbluth, A. H. Teller et E. Teller :
Equation of State Calculations by Fast Computing Machines.
The Journal of Chemical Physics , 21(6)
1087--1092, 1953.
[75]
S.P. Meyn et R.L. Tweedie :
Markov Chains and Stochastic Stability .
Communications and Control Engineering. Springer London, 2012.
[76]
R. Neal :
Bayesian Learning via Stochastic Dynamics.
In S. Hanson, J. Cowan et C. Giles, éditeurs : Advances in Neural Information Processing Systems, volume 5. Morgan-Kaufmann, 1992.
[77]
R.M. Neal :
Handbook of Markov Chain Monte Carlo , chapitre MCMC Using Hamiltonian Dynamics.
Chapman and Hall, 2011.
[78]
L.N. Nguyen, J. Liu, K. Scheinberg et M. Takàc :
SARAH: A Novel Method for Machine Learning Problems Using Stochastic Recursive Gradient.
In Doina Precup et Yee Whye Teh, éditeurs : ICML, volume 70 de Proceedings of Machine Learning Research,
pages 2613--2621, 2017.
[79]
M. Pereyra, L.V. Mieles et K. C. Zygalakis :
Accelerating proximal markov chain monte carlo by using an explicit stabilized method.
SIAM Journal on Imaging Sciences ,
13(2) 905--935, 2020.
[80]
M. Pereyra, P. Schniter, É. Chouzenoux, J.-C. Pesquet, J.-Y. Tourneret, A. O. Hero et S. McLaughlin :
A Survey of Stochastic Simulation and Optimization Methods in Signal Processing.
IEEE Journal of Selected Topics in Signal Processing ,
10(2) 224--241, 2016.
[81]
P.H. Peskun :
Optimum Monte Carlo Sampling Using Markov Chains.
Biometrika , 60(3) 607--612, 1973.
[82]
D. N. Phan, S. Bartz, N. Guha et H. M. Phan :
Stochastic Variance-Reduced Majorization-Minimization Algorithms,
SIAM Journal on Mathematics of Data Science.
6(4) 926--952, 2024.
[83]
I. Rechenberg :
Evolutionsstrategie: Optimierung technischer Systeme nach Prinzipien der biologischen Evolution. Mit einem Nachwort von Manfred Eigen.
Frommann-Holzboog, 1973.
[84]
S. J. Reddi, A. Hefny, S. Sra, B. Poczos et A. Smola :
Stochastic Variance Reduction for Nonconvex Optimization.
In Maria Florina
Balcan et Kilian Q. Weinberger, éditeurs : Proceedings of The 33rd
International Conference on Machine Learning, volume 48 de Proceedings
of Machine Learning Research, pages 314--323, New York, New York, USA, 2016.
PMLR.
[85]
H. Robbins etS. Monro :
A stochastic Approximation Method.
Annals of Mathematical Statistics , 22
400--407, 1951.
[86]
C.P. Robert :
Méthodes de Monte Carlo par chaînes de Markov,
Statistique mathématique et probabilité. Economica, 1996.
[87]
C.P. Robert et G. Casella :
Monte Carlo statistical methods.
Springer Verlag, 2004.
[88]
G. O. Roberts et J. S. Rosenthal :
Optimal scaling for various Metropolis-Hastings algorithms.
Statistical Science , 16(4) 351 -- 367,
2001.
[89]
G. O. Roberts et J. S. Rosenthal :
Optimal Scaling of Discrete Approximations to Langevin Diffusions.
Journal of the Royal Statistical Society Series B: Statistical Methodology, 60(1) 255--268, 2002.
[90]
G. O. Roberts et J. S. Rosenthal :
Coupling and Ergodicity of Adaptive Markov Chain Monte Carlo Algorithms.
Journal of Applied Probability , 44(2)
458--475, 2007.
[91]
G.O. Roberts et R.L. Tweedie :
Exponential Convergence of Langevin Distributions and Their Discrete Approximations.
Bernoulli , 2(4) 341--363, 1996.
[92]
L. Rosasco, S. Villa et B.C. Vũ :
Convergence of Stochastic Proximal Gradient Algorithm.
Appl. Math. Optim. , 82 891–917,
2020.
[93]
V. Roy :
Convergence Diagnostics for Markov Chain Monte Carlo.
Annual Review of Statistics and Its Application , 2019.
[94]
A. Salmona, V. De Bortoli, J. Delon et A. Desolneux :
Can push-forward generative models fit multimodal distributions?
In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho et A. Oh, éditeurs :
Advances in Neural Information Processing Systems, volume 35, pages
10766--10779. Curran Associates, Inc., 2022.
[95]
M.A. Schumer et K. Steiglitz :
Adaptive step size random search.
Automatic Control, IEEE Transactions on ,
AC13 270 -- 276, 07 1968.
[96]
J. Song, C. Meng et S. Ermon :
Denoising Diffusion Implicit Models.
In International Conference on Learning Representations,
2021.
[97]
Y. Song, J.N. Sohl-Dickstein, D.P. Kingma, A. Kumar, S. Ermon et B. Poole :
Score-Based Generative Modeling through Stochastic Differential Equations.
ICLR , 2021.
[98]
A. Spagnoletti, J. Prost, A. Almansa, N. Papadakis et M. Pereyra :
LATINO-PRO: LAtent consisTency INverse sOlver with PRompt Optimization, 2025.
[99]
L. Tierney :
Markov Chains for Exploring Posterior Distributions.
Ann. Statist. , 22(4) 1701--1728, 1994.
[100]
X. T. Tong, M. Morzfeld et Y. M. Marzouk :
MALA-within-Gibbs Samplers for High-Dimensional Distributions with Sparse Conditional Structure.
SIAM J. Sci. Comput. , 42(3)
A1765–A1788, 2020.
[101]
C. Toure, A. Auger et N. Hansen :
Global linear convergence of evolution strategies with recombination on scaling-invariant functions.
J Glob Optim , 86 163--203, 2023.
[102]
D.A. Van Dyk et P. Taeyoung :
Partially collapsed Gibbs samplers: Theory and methods.
Journal of the American Statistical Association ,
103(482) 790--796, 2008.
[103]
A. F. Vidal, V. De Bortoli, M. Pereyra et A. Durmus :
Maximum likelihood estimation of regularization parameters in high-dimensional inverse problems: An empirical Bayesian approach. Part I: Methodology and experiments.
SIAM Journal on Imaging Sciences ,
13(4) 1945--1989, 2020.
[104]
M. Vono, N. Dobigeon et P. Chainais :
Split-and-Augmented Gibbs Sampler—Application to Large-Scale Inference Problems.
IEEE Transactions on Signal Processing ,
67(6) 1648--1661, 2019.
[105]
Z. Wang, K. Ji, Y. Zhou, Y. Liang et V. Tarokh :
SpiderBoost and Momentum: Faster Variance Reduction Algorithms.
In NeurIPS, 2019.
[106]
G. C. G. Wei et M. A. Tanner :
A Monte Carlo Implementation of the EM Algorithm and the Poor Man's Data Augmentation Algorithms.
Journal of the American Statistical Association ,
85(411) 699--704, 1990.
[107]
S. Yang, D. Prafulla, C. Mark et S. Ilya :
Consistency models.
In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato et Jonathan Scarlett, éditeurs :
Proceedings of the 40th International Conference on Machine Learning, volume
202 de Proceedings of Machine Learning Research, pages 32211--32252.
PMLR, 23--29 Jul 2023.
[108]
Z. Zhou, P. Mertikopoulos, N. Bambos, S. P. Boyd et P. W. Glynn :
On the Convergence of Mirror Descent beyond Stochastic Convex Programming.
SIAM Journal on Optimization , 30(1)
687--716, 2020.
[109]
V. Černý :
Thermodynamical Approach to the Traveling Salesman Problem: An Efficient Simulation Algorithm.
Journal of Optimization Theory and Applications ,
45(1) 41--51, 1985.
[110]
K. Łatuszyński, B. Miasojedow et W. Niemiro :
Nonasymptotic bounds on the estimation error of MCMC algorithms.
Bernoulli , 19(5A) 2033 -- 2066, 2013.